
视频是人类理解现实世界的重要载体。相较于静态图像,视频不仅包含丰富的空间结构信息,还蕴含连续的时间动态与交互关系。如何从视频中准确理解人体运动,并在三维空间中进行连续、稳定的建模,一直是计算机视觉领域的重要研究方向之一。
近年来,单目视频3D人体重建技术取得了显著进展,使得从普通视频中恢复人体姿态成为可能。然而,在真实场景(in-the-wild)中,该任务仍面临诸多挑战。例如,在多人交互场景中,频繁的遮挡、快速运动以及视角变化,往往会导致身份关联不稳定、运动轨迹中断以及三维重建结果不连续等问题,严重制约了相关技术的实际应用。
针对上述问题,北京理工大学联合华盛顿大学、安徽大学等研究机构,提出了一种面向复杂真实场景的多人三维人体运动恢复方法RAM(Recover Any Motion)。相关研究成果以论文《RAM: Recover Any 3D Human Motion in-the-Wild》被计算机视觉领域顶级会议CVPR 2026接收。

与传统方法将“目标跟踪”与“三维重建”相对独立处理不同,RAM从整体视角出发,构建了一个统一框架,将运动感知跟踪、时序建模与动作预测有机融合,使模型能够在时间维度上形成更加完整的动态理解能力。该方法不仅关注当前帧的观测信息,还能够结合历史信息进行记忆建模,并对未来运动状态进行合理预测,从而显著提升系统在复杂场景下的鲁棒性与稳定性。
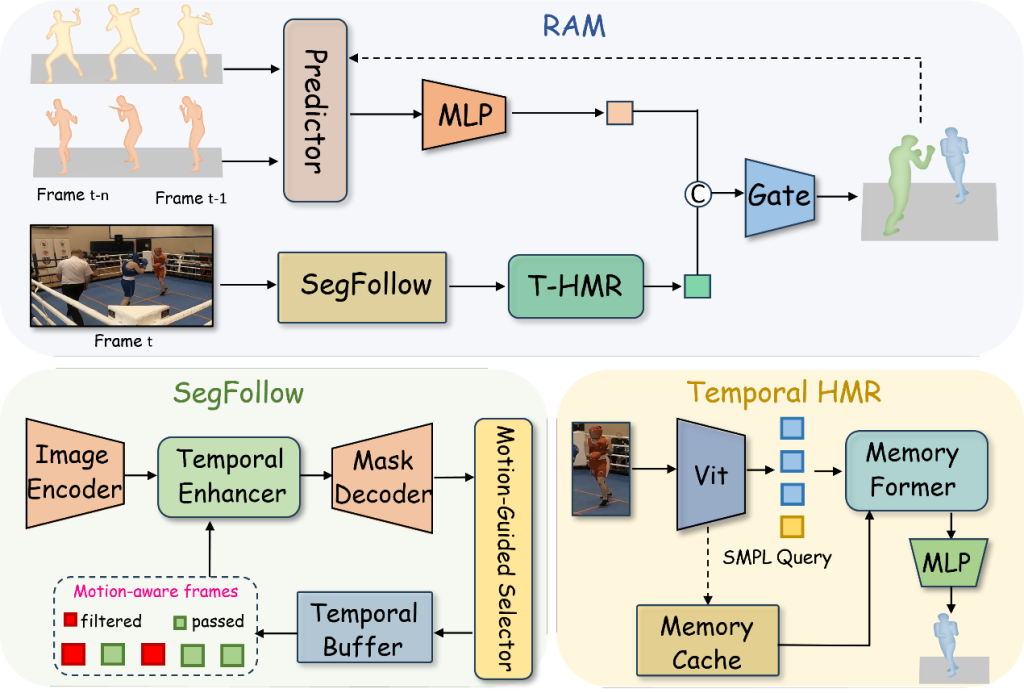
在具体方法设计上,RAM主要包含四个关键模块。首先,在跟踪阶段,研究团队提出了SegFollow模块,通过引入基于卡尔曼滤波的运动建模机制,将运动一致性信息融入目标关联过程,使模型在遮挡或外观变化明显的情况下,依然能够保持稳定的身份跟踪。这一设计有效缓解了传统方法对外观特征过度依赖的问题。
在三维重建阶段,RAM设计了基于时间记忆机制的T-HMR模块。该模块通过从邻近帧中筛选关键特征,并利用Transformer结构进行跨时间信息融合,使模型在当前帧信息不完整或存在噪声时,仍能够生成平滑且一致的三维人体结构。这种基于时序上下文的建模方式显著提升了重建结果的连续性与稳定性。
此外,为了应对目标被完全遮挡等极端情况,RAM进一步引入了动作预测模块。该模块基于历史运动序列对人体动态进行建模,并对未来姿态进行预测,从而在当前观测信息缺失时,仍能够维持运动序列的连续性。

在此基础上,研究团队设计了融合模块,对当前帧重建结果与预测结果进行自适应加权。该模块能够根据观测信息的可靠性动态调整两者的权重,在不同场景下实现最优融合,从而进一步提升整体系统的稳定性与重建精度。
实验结果表明,RAM在多个国际主流数据集上均取得了优异表现。在PoseTrack等复杂场景数据集上,该方法在身份一致性、跟踪稳定性以及三维重建精度等方面均显著优于现有方法。值得注意的是,在无需针对目标数据集进行额外训练的情况下(zero-shot设置),RAM依然能够取得领先性能,体现了其良好的泛化能力与应用潜力。

从研究意义上看,该工作不仅推动了多人三维人体运动重建技术的发展,也为视频理解任务提供了新的研究思路。通过引入时间记忆与动作预测机制,模型实现了从“逐帧处理”向“时序建模”的转变,更接近真实世界中的动态认知过程。这一方向对于体育分析、虚拟现实、人机交互以及医疗康复等应用领域具有重要潜在价值。
未来,研究团队将进一步探索更长时间尺度下的复杂交互建模问题,并推动相关技术在实际场景中的应用落地。